需求
一切技术都只是实现需求的载体,先不开门见山,来看一个实际项目中遇到的需求:
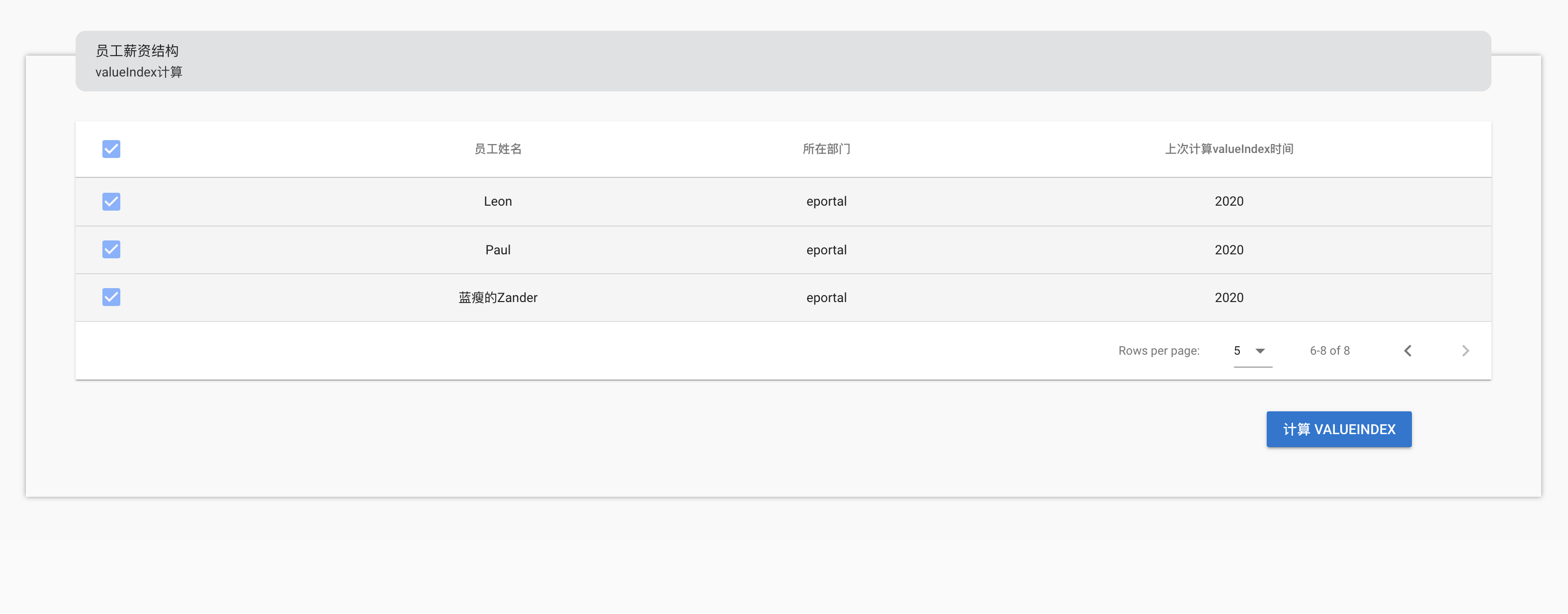 ◎ 批量操作
◎ 批量操作
要求多选后点击计算按钮发送请求,更新 MongoDB 数据库员工集合中每个所选员工文档的一个字段,而每个文档这个字段要更新的目标值都是个性化的,比如 Leon 的这个字段要更新为 500,Paul 的要更新为 999,Zander 的要更新为 100。
能为此次数据库操作提供的数据是这样的:
| |
实现
以下操作数据库的方法都是 MongoDB 提供的,Mongoose 实际是进行了移植和支持,两者原理及实现方式相同,为究其本质、探其实操,实例代码使用的是 Mongoose。
你可能会想到使用updateMany(),它支持将多个 Document 的字段更新为同一个值或者按照相同的条件来更新:
| |
但如我所说,需求要求更新的目标值是个性化的,不同的目标值之间是没有规律的。
那可否循环访问 MongoDB 一条一条地更新数据呢?否否否否否!虽然它的确能够实现需求,但是这个操作会严重影响数据库性能,在任何数据库中都要避免循环访问数据库。
| |
主角登场,bulkWrite()是 MongoDB v3.2中加入的新功能,能以特定的顺序执行 MongoDB 的写入操作,而这里的写入操作包括 insert、update、replace 等。使用方法:
| |
参数一是一个数组,表示一组数据库写操作,支持以下6个操作:
1 2 3Model.bulkWrite([ { insertOne: { "document": { "name": "Zander", ... } } ])1 2 3 4 5 6 7 8 9 10Model.bulkWrite([ { updateOne: { "filter": { "name": "Zander" }, // 查询条件,与 find()方法相同 "update": { "value_index": 100 }, // 要执行的更新操作,可以是文档,也可以是聚合管道(如$set) "upsert": false, // 可选,Boolean类型,表示如果没有查询到该文档是否执行新增操作,默认为false "arrayFilters": [ { ... }, ... ], // 可选,更新文档中的嵌套数组 "collation": { ... }, // 可选,指定更新操作的排序规则 "hint": { ... } // 可选,指定要更新文档的索引 } } ])1 2 3 4 5 6Model.bulkWrite([ { deleteOne: { "filter": { "name": "Zander" }, "collation": { ... } } } ])1 2 3 4 5 6 7 8 9Model.bulkWrite([ { replaceOne: { "filter": { "name": "Zander" }, "replacement": { "name": "Handsome", "value_index": 100, ... }, // 替换文档 "upsert": false, "collation": { ... }, "hint": { ... } } } ])
参数二是一个对象,其中包含两个设置项,writeConcern和ordered,writeConcern写入关注用以设置 MongoDB 写入操作关注程度的高低,采用默认即可。ordered用来指定是否按照顺序执行参数一中的写入操作,默认为true ,若设置为无序,MongoDB 会对操作进行重排序以提高性能,具体应取决于你的写入操作是否是有序的。
使用bulkWrite()完成上面的需求:
| |
bulkWrite()操作的返回值包括:
| |
insert()和upsert()操作的区别在于前者不需要进行查询操作,直接将数据插入集合中,而后者会根据条件先在集合中查找数据,找到了则更新,找不到再执行插入操作。
还有一点是bulkWrite()需要使用try..catch捕获错误,原因是在执行bulkWrite()过程中,如果遇到了 Write Concern 以外的错误(即不可控的错误),有序操作(ordered为true)将在发生错误后停止并返回这单个错误,无序条件(ordered为false)下则跳过遇到的错误继续处理操作队列中所有剩余的写操作,最后在 writeErrors 中返回每个错误。